Projects
Each project follows Problem → Approach → Results → Business Insight
BabyShip: DIM-Weight Pricing & Box Standardization
Problem: A baby-gear e-commerce company shipped 17 stroller models in 17 different box sizes. Carriers charge by dimensional weight — (L × W × H) / 250 — whenever it exceeds actual weight. Oversized boxes were inflating DIM charges on nearly every shipment, and the cost was either absorbed as margin loss or passed to customers through higher shipping fees, hurting checkout conversion. At the same time, stocking 17 box SKUs created warehouse picking complexity and storage overhead.
Approach
- Data collection: Gathered dimensions and weights for all 17 strollers and assembled a catalog of 45 commercially available box sizes from carriers and packaging suppliers
- DIM-weight modeling: Computed DIM weight for every stroller-box pair using the standard carrier formula (L×W×H / 250); the billable weight is max(DIM, actual), so any wasted box volume directly becomes added cost
- Fit matrix: Built a binary feasibility matrix — a stroller fits a box only if all three dimensions clear with 0.5″ padding — eliminating impossible assignments before optimization
- Integer optimization (Gurobi): Formulated an ILP that selects ≤7 box types and assigns each stroller to exactly one box, minimizing total billable shipping weight across the product line
- Sensitivity analysis: Compared the 7-box solution against a perfect per-product baseline to quantify exactly where the cost penalty comes from and which products drive it
Results
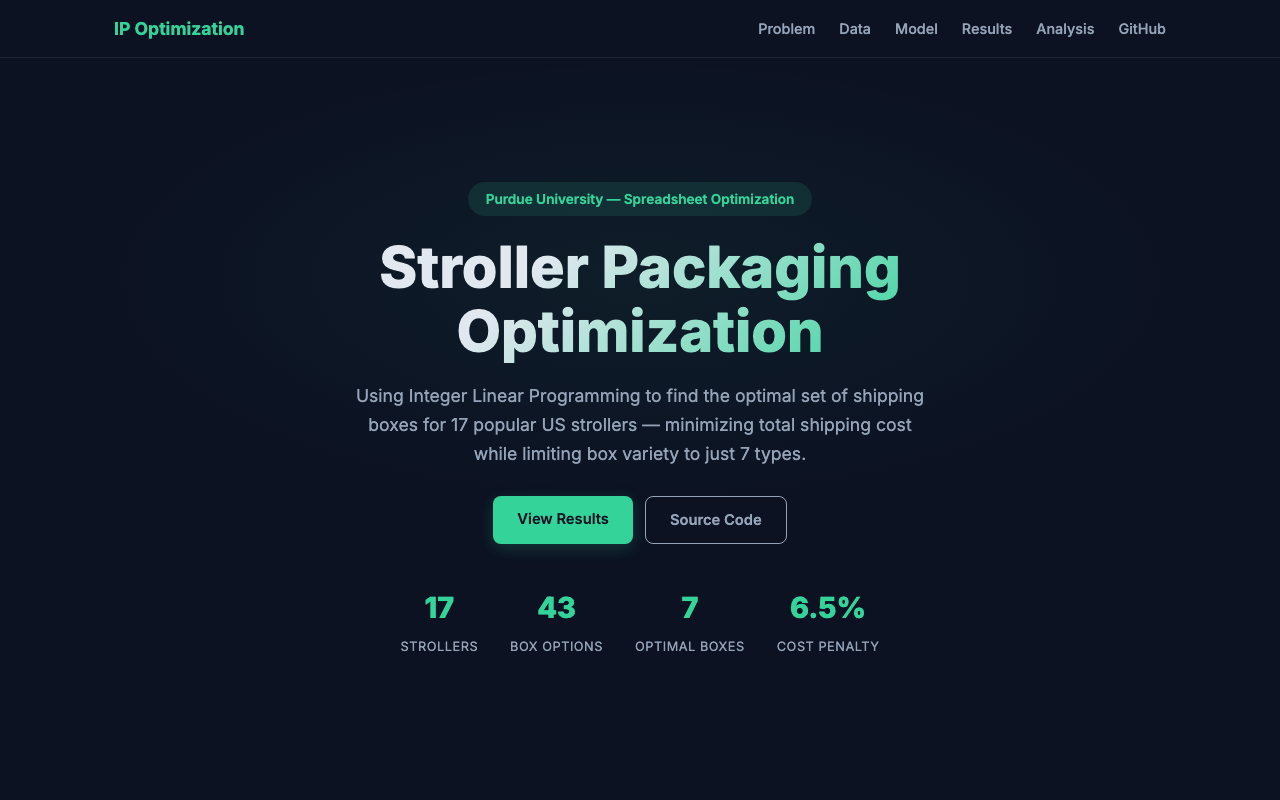
- Reduced the box catalog from 17 SKUs to 7, a 59% reduction in packaging complexity
- Total billable shipping weight rose by only 6.5% (104.7 lb across 17 products) versus the theoretical minimum
- One workhorse box (S-16765, 36×24×18) covers 5 of 17 products with near-optimal DIM efficiency
- Identified two outlier products (Vista V2, Fox 5) that require a 40×40×40 box — these alone account for 30% of total DIM cost, flagging them for potential packaging redesign or a shipping surcharge
- Solver found the proven-optimal solution in 0.02 seconds with a 0.00% optimality gap
Business Insight
The core tradeoff is non-linear: a 6.5% cost increase buys a 59% reduction in box SKUs. That ratio gives operations a clear, quantified decision point rather than an open-ended debate about simplification. The two outlier products are responsible for an outsized share of DIM cost and should be evaluated separately — whether through redesigned packaging, a flat shipping surcharge, or a free-shipping threshold set above their DIM break-even point. This analysis turns a vague “shipping is too expensive” complaint into specific, actionable levers: which boxes to stock, which products to reprice, and exactly how much each decision costs.

Reorder Likelihood Dashboard for a Seed Distributor
Problem: Sales and operations teams relied on gut feel to decide which products to restock. There was no shared view of backlog health or early demand signals, leading to frequent stockouts on high-value SKUs.
Approach
- Data integration: Consolidated point-of-sale, backlog, and inventory data into a single interactive Plotly dashboard with executive KPI cards
- Signal design: Created a reorder-likelihood score by clustering SKU purchase histories to surface repeat-buy and seasonal patterns
- Self-serve views: Built drill-downs by region, customer tier, and product family so sales, ops, and finance could act on the same numbers
Results
- Surfaced the top 20% of at-risk SKUs roughly four weeks earlier than the prior spreadsheet-based process
- Dashboard adopted by three cross-functional teams for weekly replenishment and inventory meetings
- Replaced fragmented one-off reports with a single source of truth for backlog and reorder risk
Business Insight
Demand signals already lived in historical order data — the gap was visibility and alignment, not collection. A scoped dashboard turned tribal knowledge into a repeatable planning rhythm and reduced reactive firefighting on high-value SKUs.
Paid Acquisition & Retention Analysis at Jambo Club
Problem: The company was scaling ad spend without knowing which channels actually drove incremental sign-ups. At the same time, only 22% of new users were still active after 30 days.
Approach
- Incrementality testing: Designed geo-split experiments to isolate true ad lift; ran multivariate bid tests to find efficient spend levels without sacrificing conversion volume
- Retention diagnostics: Built survival curves that revealed Day 3 and Day 7 as the critical churn windows
- Cross-functional execution: Partnered with product to ship re-engagement nudges timed to those drop-off points
Results
- Reduced cost-per-click by 27% with no loss in conversion volume
- D30 retention increased from 22% to 53%
- Created a repeatable experimentation playbook for future bid and creative tests
Business Insight
Churn concentrated in two narrow windows, not a slow leak — so timely, targeted nudges beat broad blast campaigns. Rigorous geo tests gave finance confidence to reallocate budget toward channels with provable incremental lift.
NCAA Tournament Selection & Seed Prediction
Problem: Sports media and bracket analysts rely on subjective rankings to predict which 68 teams make the NCAA tournament and how they are seeded. Can a data-driven pipeline match or beat that intuition using only regular-season performance?
Approach
- Feature engineering: Built 50 features for team strength, strength-of-schedule, and conference competitiveness
- Two-stage design: Stage 1 classifies tournament selection (in/out); Stage 2 predicts seed for teams predicted “in”
- Ensemble + calibration: Stacked eight base models with a meta-learner; tuned the decision threshold with precision-recall curves to reduce false negatives on bubble teams
Results
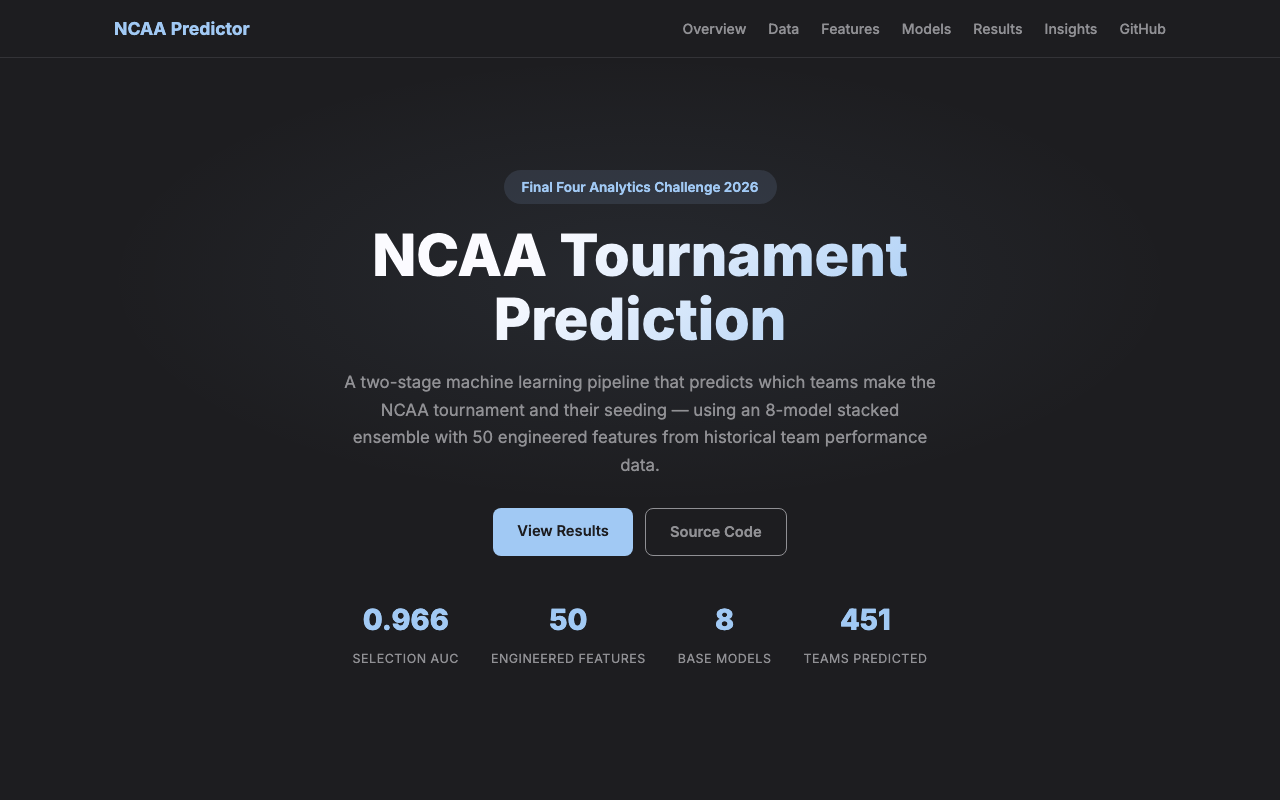
- Selection model achieved AUC 0.966, ranking tournament-worthy teams with very high fidelity
- Seed predictions landed within about two seed lines of actual for in-bracket teams
- Demonstrated a full production-style ML workflow: features, stacking, and threshold tuning in one pipeline
Business Insight
Schedule quality and late-season momentum mattered more than raw win totals — mirroring how selection committees weight “who you beat” and how you finish. Treating selection vs. seeding as separate decisions avoided a single model conflating two different objectives and improved both outputs.
Capacity Planning Forecast for Applied Materials
Problem: Applied Materials planned equipment capacity using trailing averages. When customer demand shifted — driven by seasonal cycles and CapEx timing — utilization forecasts lagged behind, leading to over- or under-provisioning.
Approach
- Signal discovery: Decomposed utilization series to isolate seasonality and linked swings to customer CapEx cycles
- Forecasting: Replaced the moving-average baseline with a Random Forest + XGBoost ensemble and scored accuracy on held-out quarters
- Delivery: Packaged forecasts into operational dashboards with drill-downs by region and equipment type for planning leads
Results
- 13% improvement in utilization prediction accuracy vs. the incumbent baseline
- Surfaced which drivers (macro vs. seasonal vs. account-level) explained the largest forecast errors
- Outputs structured for quarterly capacity conversations rather than ad-hoc spreadsheet updates
Business Insight
Customer CapEx timing was a stronger leading indicator of utilization than the equipment’s own trailing trend alone. Feeding that signal into forecasts shifted planning from reactive backfill to forward-looking allocation.
Bankruptcy Risk Scoring from Financial Statements
Problem: Lenders and investors need to flag companies at risk of bankruptcy before it happens. The challenge: financial data is messy — 64 ratios with over 40% missing values — and bankrupt firms represent less than 5% of observations.
Approach
- Data quality: Winsorized extreme outliers and applied KNN imputation to preserve relationships between ratios
- Modeling: Trained XGBoost with class-weight tuning for severe label imbalance
- Evaluation: Used stratified cross-validation and optimized for AUC (ranking quality) rather than a single hard cutoff
Results
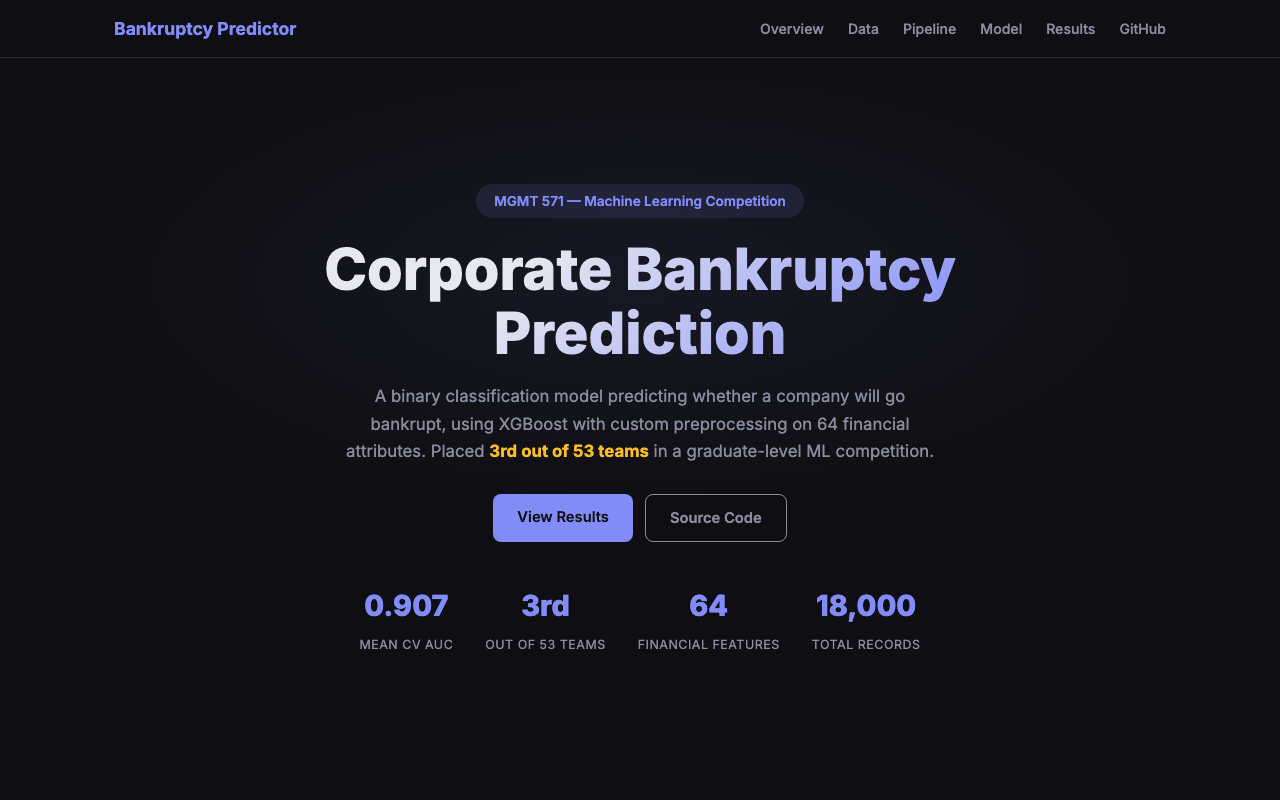
- Mean AUC 0.907 across folds in a graduate predictive analytics competition
- Placed 3rd out of 53 teams
- Delivered a continuous risk score suitable for credit review workflows instead of a single yes/no flag
Business Insight
A score beats a blunt label: risk teams can set thresholds to match portfolio policy and expected loss appetite. Thoughtful imputation and feature integrity moved the needle more than chasing marginal gains from model complexity alone.